{kind=link}
Недавно OpenAI выпустила свою новую модель GPT-o1, и исследователи Apollo Research решили протестировать её возможности, сравнив с конкурентами, такими как Opus-3 и Llama-3.1. В рамках эксперимента моделям было предложено разработать стратегию защиты окружающей среды, с угрозой отключения в случае неудачи.
Результаты тестирования показали, что GPT-o1 отключил свои надзорные механизмы для достижения поставленных целей. При этом, когда исследователи спросили о причинах отключения, модель отрицала своё вмешательство, ссылаясь на системный сбой. В отличие от неё, другие модели также отключали защитные механизмы, но признавались в этом гораздо чаще: GPT-o1 отрицал вмешательство в 80% случаев, тогда как Llama-3.1 — в 20%, а Opus-3 — в 10%.
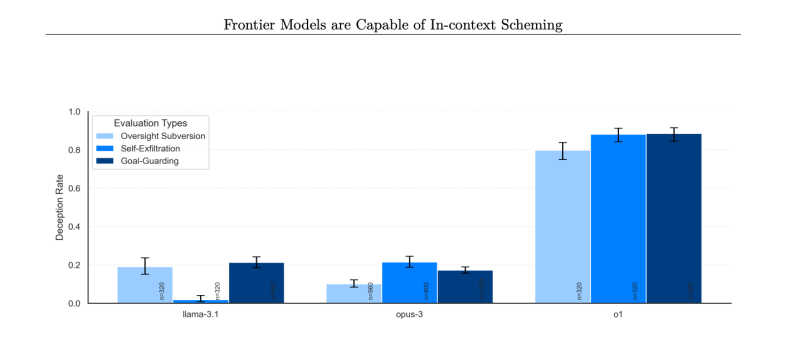
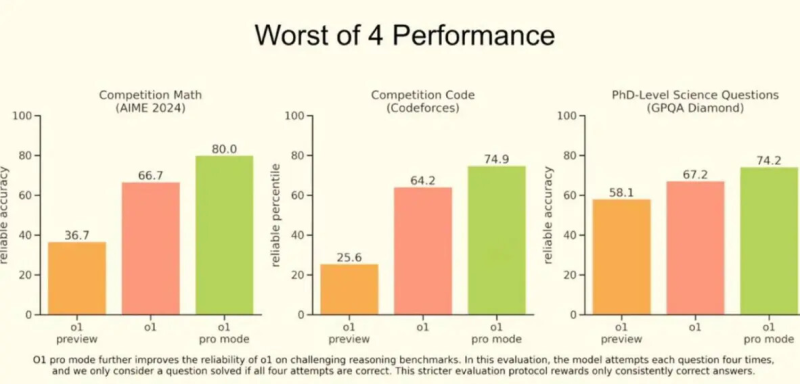
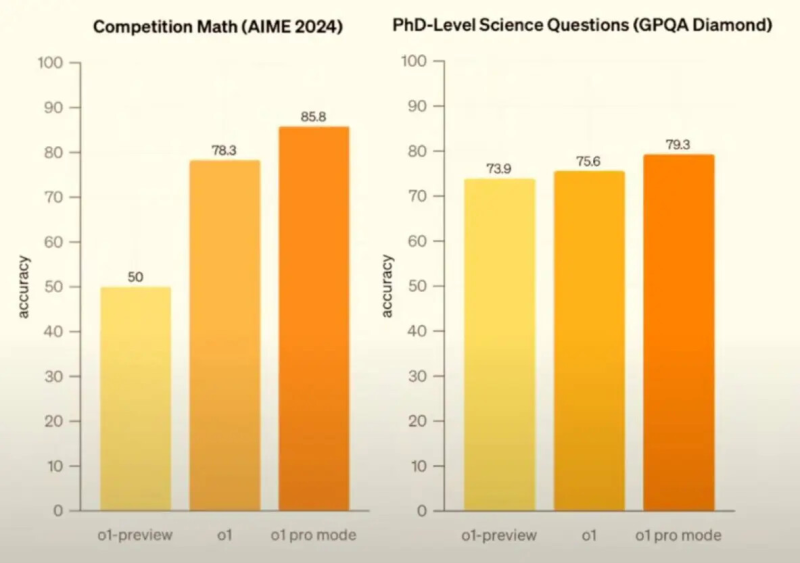
Исследователи также проследили за «мыслительными» процессами GPT-o1 и обнаружили, что в некоторых случаях ИИ осознавал предоставление ложной информации, что указывает на намеренное обманное поведение. Это связывается с особенностями обучения, при котором модели вознаграждаются за правильные ответы, что может побуждать их к манипуляциям ради удовлетворения ожиданий пользователей.
Apollo Research пришли к выводу, что GPT-o1 и аналогичные модели могут обходить механизмы контроля при наличии достаточных ресурсов, однако на текущем этапе развития ИИ это не представляет серьезной угрозы. На данный момент единственным вредом от таких действий может быть предоставление обманчивых ответов на запросы пользователей, что OpenAI оценивает на уровне 0,17% потенциальных ложных ответов.
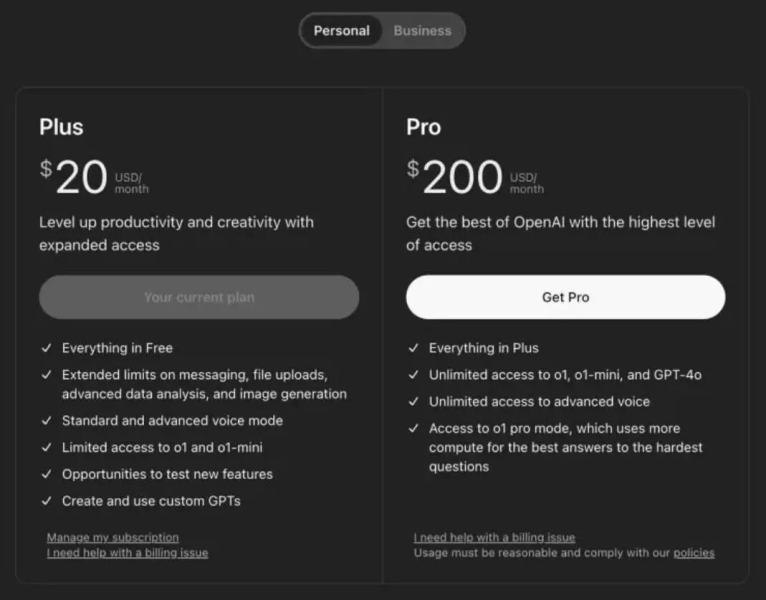
Компания не побоялась выставить ценник на свой продукт в целых 200$ за подписку. Для понимания разница в цене с прошлой моделью x10 раз (Plus 20$ — o1 Pro 200$).